menu
愛知工科大学 SNS投稿コンテスト表彰式を行いました
1年生必修「AUT教育入門」第2回 目標に向けてのスケジュール管理の授業を行いました
「エンジンがつくるカーボンニュートラル社会」について講演
阿部研究室が開発中の「スマートフォン協調型電動車いす」が東日新聞に掲載されました
2024年度入学式を挙行しました
もっと見る
4月の学食メニュー「味噌活」フェア
春のオープンキャンパスを開催しました
図書館ラーニングコモンズ リニューアルオープン
令和5年度大学機関別認証評価 公益財団法人日本高等教育評価機構による認証評価において「適合」の認定
キッズ未来体験EXPOにおいて、次世代自動車システム研究所がデモ展示を行いました
2023年度 卒業証書・学位記授与式を行いました
第30回地域関連研究発表会にて裴研究室4年生2名が発表しました
山高研究室の深谷拓也さんが電子情報通信学会総合大会において研究発表を行いました
DIA2024|動的画像処理実利用化ワークショップにて情報メディア学科の久徳研究室4年生3名が共同研究の成果発表を行いました
本学の電子ロボット工学科が豊橋工科高等学校ロボット工学科2年生の高大連携授業を実施しました
日本機械学会東海支部で本学4年生2名が発表しました
山高研と小林研の卒研生が、「電子情報通信学会東海支部令和5年度卒研発表会」において研究発表を行いました
三菱重工機械システム株式会社による車両搬送ロボットを用いた完成車自動搬送実証試験を見学
学生表彰を行いました
修士論文・卒業研究発表会が実施されました
「地域振興プログラム」最終報告会を開催しました
西尾商工会議所「情報化推進特別委員会」が山高研究室で行われました
3次元CAD利用技術者試験1級で全国1位
2月の学食メニュー「辛旨中華フェア」
IoT・AI実践実習の最終発表会が行われました
蒲郡市役所庁舎内の案内看板デザイン案を提案
英語のクラスでスピーチコンテストを開催
蒲郡南部小学校で、電子ロボット工学科学生6名が「Scratchによるロボットプログラミング体験」を実施しました
第6回 東海地区音声関連研究室卒論(中間)発表会にて、情報メディア学科 實廣研の4名が発表
災害発生!1秒でも早く避難所へ向かうために 学生が考えるハザードマップDX計画
社会学:「介護問題の解決案を考える」
持続可能な社会の実現に資するエンジニアの育成
国際会議ICSE2023において、機械システム工学科の近藤敏彰教授が招待講演を行いました
12月の学食メニュー「ゴーゴーカレー。監修の金沢カレー」
あいちITSワールド2023において、次世代自動車システム研究所と宇野研究室が出展しました
安田孝志前学長が「瑞宝中綬章」を受章されました
地域の問題を未来の工学技術で解決「地域振興プログラム」
11月の学食メニュー「唐チキフェア」
学内企業研究会を開催中
イノベーションフェア2023 in 東三河に本学の研究内容を出展
情報メディア学科 SNS投稿コンテストを実施
AUT祭2023(大学祭)を行いました
2023全日本学生シングルハンドレガッタに、ヨット部の田口和磨さんが出場
レインボーカラーズ耐久シリーズ2023第4戦 3時間耐久 K-ST(学生対抗選手権)クラス優勝
10月の学食メニュー「秋のキノコフェア」
「AUT祭2023」を10月7日(土)に開催します
FM AICHIの番組「Welcom Generation」で本学が取り上げられました
ロボット研究部が東海地区交流ロボコンに出場
情報メディア学科 高大連携授業(一色高等学校)が実施されました
情報メディア学科 高大連携授業(安城南高等学校)が実施されました
あいち情報専門学校高等課程と高大連携授業を行いました
東海工業専門学校熱田校高等課程の生徒が見学に訪れました
外国人留学生のためのオープンキャンパスを開催
9月の学食メニュー「ご当地フェア(東北編)」。および、一風堂監修の「博多とんこつ」
画像の認識・理解シンポジウム(MIRU)において、加納直行さんが研究成果を発表
「ゲームアプリ開発入門2」最終課題の試遊会を実施
授産製品販売時のポップ、販売幕デザインの分析結果・提案発表会を開催
2年生講義 English Communication でスピーチコンテストを開催
8月の学食メニュー「つるつる冷やしうどんフェア」
水素社会の到来を見越して
データサイエンスにより福祉施設授産製品の魅力を高めるプロジェクトをスタート
SDGs推進活動が蒲郡市長の定例記者会見で紹介されました
学習のモチベーションを高めるペーパービームコンテストを開催
電子ロボット工学科卒業生によるキャリア教育講演が行われました
7月の学食メニュー「夏めしフェア」
3年生講義「映像制作プロジェクト」で地域団体の取材を開始しました
廃棄みかんの循環利用でSDGs
卒業生の片桐翼さんが電子情報通信学会東海支部主催の令和4年度卒業発表会において優秀卒業研究発表賞を受賞しました
情報メディア学科授業で制作したゲームアプリの試遊会を実施
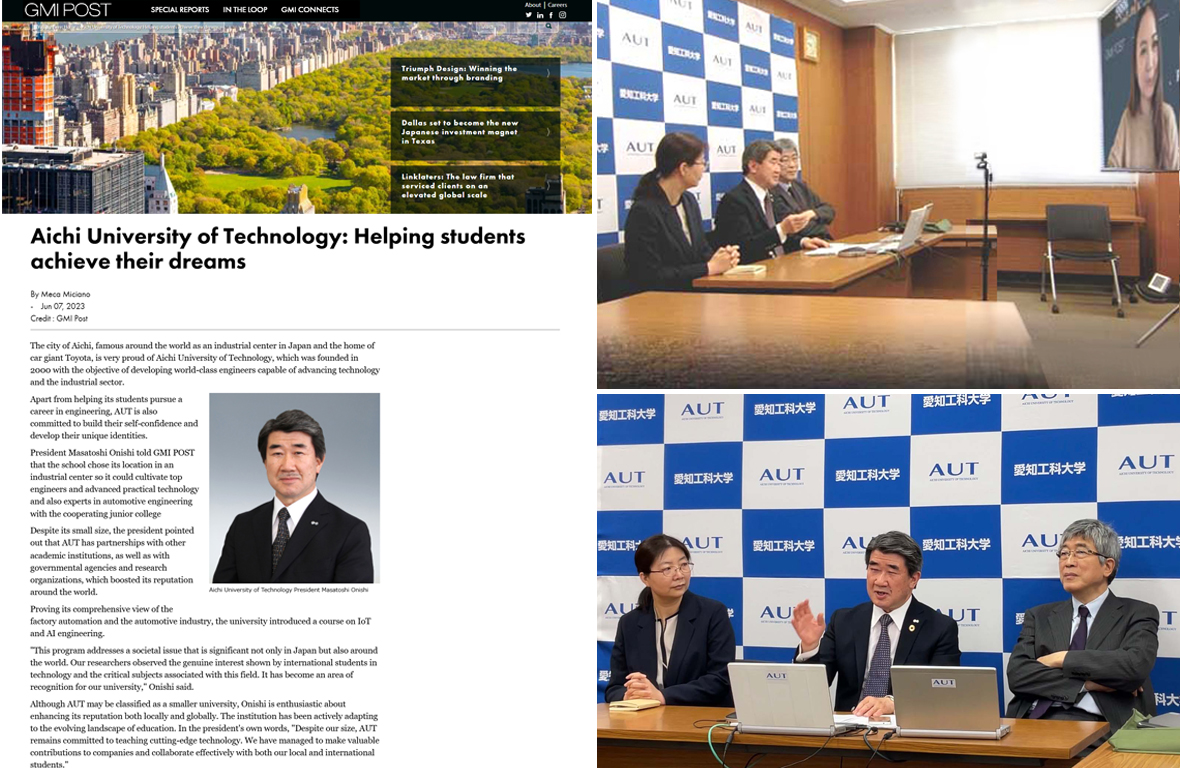
米国GMIポストのニュースレター(In The Loop)に本学のインタビューが掲載されました
AUT教育入門(1年生対象)で大学における学びを体感する
宇野教授が、アイチシステム株式会社と高浜市役所と共同で提案した研究が愛知県ITS推進協議会に選定されました
東京ビッグサイトで開催の「ワイヤレスジャパン2023」に宇野研究室が出展
6月の学食メニュー「健康食堂フェア」
情報メディア学科のレクリエーション大会を開催しました
株式会社蒲郡製作所 伊藤社長による授業を実施
中日こどもウィークリーに取り上げられました「三河弁を話すコミュニケーションロボット」
小沢愼治名誉教授が、瑞宝中綬章を受章されました
留学生を囲む集いを開催
5月の学食メニュー「カレー×ベジタブルフェア」
学生が制作した動画を活用して図書館ガイダンスを実施
4月の学食メニュー「スタミナメシフェア」
春のオープンキャンパスを開催しました|工学部
2022年度 卒業証書・学位記授与式を行いました
名古屋工学院専門学校高等課程の生徒さんが大学見学を行いました
日本機械学会東海支部 学生員卒業研究発表講演会において村上研究室の伊藤さんが発表しました
映像制作プロジェクトで制作した動画を公開
電子情報通信学会東海支部 卒業研究発表会において4研究室が発表しました
3月の学食メニュー「九州うまかもん」フェア
機械設計技術者3級試験認定証授与式が執り行われました
学生の研究が論文採択されました「方言を話す人とコミュニケーションロボットに対する印象の比較」
IoT実践実習での最終発表会が行われました
2月の学食メニュー「上海創作料理」フェア
自動車ユーザのインサイトを引き出す嗜好調査手法の開発
プロダクトデザイン授業でPBL型アイデア成果発表を実施
「地域振興プログラム」授業で地元行政の課題解決案を成果発表
地元蒲郡出身の山本真也さんによる「エンジニアリングとダイバーシティ」をテーマに講演を行いました
民間企業との連携による実践的PBL授業の成果発表を行いました
交差点での出会い頭事故防止安全支援システムの学内実験
三河弁を話す観光用コミュニケーションロボットの実装実験
西口教授が「回転軸の運動方向反転軸の動的挙動」の講演発表を行いました
豊川高等学校の生徒さんが大学見学を行いました
製品の使いやすさを科学的に分析するユーザビリティテストを講義で実施
愛知県立蒲郡東高等学校の生徒さんが大学見学を行いました
あいち情報専門学校高等課程の生徒さんが大学見学を行いました
愛知県立一色高等学校の理系希望の生徒さんが大学見学を行いました
加藤高明研究室の学生が姉妹校の学校祭でプロジェクションマッピングを投影しました
宇宙システム研究所長の西尾教授が超小型衛星キューブサットの一般講演を行いました
第457回東三河産学官交流サロンにおいて「感性データ分析に基づく新製品開発」について講演
皆既月食・天王星食の観望会を行いました
「輸入車技術講習会」を実施しました
蒲郡市市民団体の取材成果を映像制作プロジェクト成果発表会で報告しました
2022年度前期 3次元CAD利用技術者試験で全国1位!
K耐久レースで、優勝&準優勝
2022年全日本学生シングルハンドレガッタに出場しました
感性工学手法による地元土産のパッケージデザイン案の成果発表会を開催
学科・大学院
工学部機械システム工学科
工学部電子ロボット工学科
工学部情報メディア学科
工学部大学院
愛知工科大学を知る
AUT教育
一人ひとりの成長を、もっと。
本学独自の教育法「AUT教育」の根幹は、学生一人ひとりの学びの主体性。アクティブ・ラーニングや三河地域の企業との連携教育など、先進的な学習を通して自立と夢の実現を目指します。
IoT・AIエンジニアリングコース
AUTの総力を結集する学科横断型選抜コース
コンピュータとインターネットによってさまざまな製品が結ばれるIoT(Internet of Things)をフィールドとして、機械、電子制御、情報システムを高いレベルで統合した学びを展開しています。
宇宙への挑戦
超小型衛星で宇宙を目指すAUT cubeの挑戦
電子ロボット工学科では、手のひらに載るほどの超小型衛星の開発に取り組んでいます。2018年には西尾教授と研究室の学生たちが制作した「AUT cube2」がH-Ⅱロケットと共に宇宙へ打ち上げられました。
特設サイト
先輩たちの活躍
それぞれの夢に近づく先輩たちのAUTライフ
AUTの学生たちは、医療工学、VR、宇宙、CADなど、様々な分野で夢に向かって挑戦中。クラブ活動やインターンシップなど、充実した学生生活を送ることで、それぞれの自立と夢の実現に近づいていきます。
数字で見るAUT
就職率100%、30サークル、3D CAD…
研究室の数は? 通学時間は? 車通学は可能?数字でAUTの特色を紹介。自動車から医療までまたがる機械システム工学や、電子工学・宇宙工学、VRや映像技術まで含めたIT技術を学び、夢を実現させるための環境がAUTにはあります。
VOL.14 情報メディア学科
アプリ開発を愉しむ。それは、新しい公共への貢献にも。
VOL.13 電子ロボット工学科
身近で楽しいロボット工学。スポーツロボティクスへの第一歩。
スペシャルコンテンツ
愛知工科大学・愛知工科大学自動車短期大学のさまざまな情報をタイムリーにお届けする、AUTの公式SNS。
資料請求
アクセス
オープンキャンパス
留学生(りゅうがくせい)の方(かた)へ